我对这个网络抓取非常新.我正在使用crawler4j来抓取网站.我通过抓取这些网站收集所需的信息.我的问题是我无法抓取以下网站的内容.如果您观察到附加的屏幕截图,则它有三个名称(在红色框中突出显示).如果单击其中一个...
”crawler; Ajax网络爬虫“ 的搜索结果
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
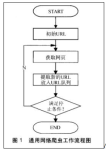
1.1 什么是网络爬虫 1.1.1 爬虫的简单定义 1.1.2 爬虫的分类 1.2 为什么需要爬虫 1.2.1 爬虫的用途 1.2.2怎么做爬虫 第二章 爬虫的基本常识 2.1 爬虫的合法性问题 2.2 爬虫的准备工作:网站的背景调研 ...
蜘蛛侠 这是作为OWASP OWTF的Google Summer of Code 2014项目的一部分开发...此扩展还通过映射 WEB 2.0(或 Ajax 丰富的应用程序)来补充OWTF扫描引擎。 它使用 Python 的 Selenium 绑定和 lxml 来完成所有繁重的工作。
基于Ajax的网络信息抽取系统的设计与实现,王洪明,,基于网络爬虫的小型信息系统已得到广泛关注和应用,但随着Ajax技术应用的增多,传统网络爬虫逐渐不能满足用户获取的信息需求,传��
孙建言 马雨欣 武文杰摘要:通过Python和Scrapy框架的使用,实现了一个对电商商品和商品评价信息的...关键词:网络爬虫;Python;数据分析中图分类号:G434 文献标识码:A文章编号:1009-3044(2019)26-0061-03开放科学...
网络爬虫(Web crawler),是一种“自动化浏览网络”的程序,或者说是一种网络机器人。它们被广泛用于互联网搜索引擎或其他类似网站,以获取或更新这些网站的内容和检索方式。它们可以自动采集所有其能够访问到的...

网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。简单来说就是你写个脚本去抓别人网页上的内容。举个例子,上面这张图片是前程无忧招聘网站上关于python招聘的一些...
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索...
谷歌 Ajax 爬虫 机架中间件遵循 Google Ajax Crawling Scheme,使用无头浏览器渲染 JS 重页面,并将渲染状态的 dom 快照提供给请求搜索引擎。 该计划的详细信息可以在以下位置找到: : 使用安装 gem install google_...
再后来随着js的兴起,也处于站点的美观和易于维护,越来越多的ajax异步请求方式数据站点。[不扯犊子了 ,马上上示例] 参与工作时间不是很长,但工作期间一直做不同的爬虫项目。对常见的页面数据获取,...
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索...
ISBN 978-7-111-62593-3 CNY79.00题名 Python网络爬虫从入门到精通=Python web crawler from entry to proficiency / 吕云翔,张扬,韩延刚等编著 eng出版信息 北京: 机械工业出版社, 2019载体形态项 10,333页: 图;...
网络爬虫,简称爬虫(Crawler),是一种自动化程序,能够模拟人类用户的行为,访问网页并提取所需的数据。爬虫可以从互联网上的各种网站中抓取信息,包括文字、图片、视频等。它们能够自动化地浏览网页、解析内容,...
网络爬虫(Web Spider)又称网络蜘蛛、网络机器人,是一段用来自动化采集网站数据的程序。如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络爬虫不仅能够为搜索引擎采集网络信息,而且还可以...
网络爬虫(Web crawler)也叫做网络机器人,可以代替人们自动地在互联网中进行数据信息的采集与整理。它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,可以自动采集所有其能够访问到的页面内容,以...
开始之前请先确保自己安装了...在项目文件夹安装两个必须的依赖包SuperAgent(官网是这样解释的)-----SuperAgent is light-weight progressive ajax API crafted for flexibility,readability,and a low learning cur...

uzbdict 爬虫从基于 Ajax 的页面检索字典如何使用apt-get install python-setuptoolseasy_install pippip install virtualenvvirtualenv env --no-site-packagessource ./env/bin/activategit clone ...
2019独角兽企业重金招聘Python工程师标准>>> ...
探索技术宝藏:crawler-userscript - 一个强大的网络爬虫用户脚本库 项目地址:https://gitcode.com/zjh1943/crawler-userscript 项目简介 如果你是一名热衷于数据挖掘、网页抓取或是想要提升浏览器体验的技术爱好者...
网络爬虫技术总结 http://mp.weixin.qq.com/s?__biz=MzI3MTI2NzkxMA==&mid=2247484132&idx=1&sn=8db587fabc3c630decf0419b6130770e&scene=23&srcid=0720ZByjAlOM9YC5c76N9uKU#rd 对于大数据...
对于大数据行业,数据的价值不言而喻,在这个信息爆炸的年代,互联网上有太多的...网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索...
delete支持爬取JS动态渲染(或ajax)的页面支持代理支持自动保存至数据库/文件常用字符串,日期,文件,加解密等函数支持插件扩展(自定义执行器,自定义方法)任务监控,任务日志支持HTTP接口支持Cookie自动管理...
推荐文章
- 大数据技术未来发展前景及趋势分析_大数据技术的发展方向-程序员宅基地
- Abaqus学习-初识Abaqus(悬臂梁)_abaqus悬臂梁-程序员宅基地
- 数据预处理--数据格式csv、arff等之间的转换_csv转arff文件-程序员宅基地
- c语言发送网络请求,如何使用C+发出HTTP请求?-程序员宅基地
- ccc计算机比赛如何报名,整理:加拿大的CCC是什么,怎么报名?-程序员宅基地
- RK3568 学习笔记 : ubuntu 20.04 下 Linux-SDK 镜像烧写_rk3568刷linux-程序员宅基地
- Gradle是什么_gradle是干嘛的-程序员宅基地
- adb命令集锦-程序员宅基地
- 【Java基础学习打卡15】分隔符、标识符与关键字_java分隔符有哪三种-程序员宅基地
- Python批量改变图片名字_python批量修改图片名称-程序员宅基地